Pooling Layers¶
The convolution layer creates activations that are 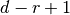 long on each axis.
Adjacent activities in each of these feature maps are often related to each other.
This is because, in imaging contexts, most patterns spread across a few pixels.
We want to avoid storing (and processing) these redundancies and preferably only use the most prominent of these features.
long on each axis.
Adjacent activities in each of these feature maps are often related to each other.
This is because, in imaging contexts, most patterns spread across a few pixels.
We want to avoid storing (and processing) these redundancies and preferably only use the most prominent of these features.
This is typically accomplished by using a pooling or a sub-sampling operation.
Pooling is done typically using non-overlapping sliding windows, where each window will sample one activation.
In the context of images, pooling by maximum (max-pooling) is typically preferred.
Pooling by 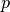 (widow size of ) reduces the sizes of activations by fold.
A pooling layer has no learnable components.
(widow size of ) reduces the sizes of activations by fold.
A pooling layer has no learnable components.
Implementation¶
A maxpooling layer for 4D tensors can be implemented as follows:
# The pooling size and strides are 4 dimensions also.
pool_size = (1,2,2,1)
stride = (1,2,2,1)
padding = 'VALID'
output = tf.nn.max_pool ( value = input,
ksize = pool_size,
strides = stride,
padding = padding,
name = name )
The only difference is between theano and tensorflow syntactically is that the arguments are different
from theano.pool2d(). The arguments for pooling size (ksize) and strides are 4 dimensions
as well.
The shapes of inputs remain consistent with the conv2d module as discussed before.
The entire layer class description can be found in the lenet.layers.max_pool_2d_layer() method.