CNN Architecture Philosophies¶
Analogous to model design in most of machine learning and to the practice of hand-crafting features, CNNs also involve some degree of skilled hand-crafting. Most of hand-crafting involves the design of the architecture of the network. This involves choosing the types and number of layers and types of activations and number of neurons in each layer. One important design choice that arises particularly in image data and CNNs, is the design of the receptive fields.
The receptive field is typically guided by the size of filters (weights) in each layer and by the
use of pooling layers.
The receptive field grows after each layer as the range of the signal received from the input layer
grows progressively.
There are typically two philosophies relating to the choice of filter sizes and therefore to the
receptive fields.
The first was designed by Yann LeCun et al., [LBBH98], [LBD+90]
and was later re-introduced and widely preferred in modern day object categorization by Alex Krizhevsky et al.,
[KSH12].
They employ a relatively large receptive field at the earlier layers and continue growing with the
rate of growth reducing by a magnitude.
Consider AlexNet [KSH12].
This network won the ImageNet VOC challenge [DDS+09] in 2012 which involves
recognizing objects belonging to 1000 categories with each image being 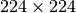 in size.
This network has a first layer with
in size.
This network has a first layer with 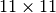 convolutional filters (which are strided by
convolutional filters (which are strided by 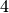 pixels),
followed by a
pixels),
followed by a 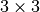 pooling (strided by
pooling (strided by 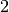 ).
The next layer is
).
The next layer is 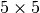 , followed by , each with their own respective pooling layers.
, followed by , each with their own respective pooling layers.
The second of these philosophies is increasing the receptive field as minimally as possible.
These were pioneered by the VGG group [SZ14] and one particular implementation
won the 2014 ImageNet competition [DDS+09].
These networks have a fixed filter size, typically of and have fixed pooling size
of 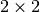 at some checkpoint layers.
These philosophies aim to hierarchically learn better filters over various growth of small receptive fields.
The classic LeNet from Yann LeCun is a trade-off between these two case studies [LBBH98].
at some checkpoint layers.
These philosophies aim to hierarchically learn better filters over various growth of small receptive fields.
The classic LeNet from Yann LeCun is a trade-off between these two case studies [LBBH98].

Fig. 8 Filters learnt by CNNs.
The figure above show various filters that were learnt by each of these philosophies at the first layer that is closest to the image.
From left to right are filters learnt by VGG (), a typical Yann LeCun style
LeNet () and a AlexNet ().
It can be noticed that although most first layer filters adapt themselves to simple edge filters and Gabor filters, the
filters are simpler lower-dimensional corner detectors while the larger receptive field
filters are complex high-dimensional pattern detectors.
Although we studied some popular network architecture design and philosophies, several other styles of networks also exists. In this section we have only studied those that feed forward from the input layer to the task layer (whatever that task might be) and there is only one path for gradients to flow during back-prop. Recently, several networks such as the GoogleNet [SLJ+15] and the newer implementations of the inception layer [SVI+16], [SIVA17], Residual Net [HZRS16] and Highway Nets [SGS15] have been proposed that involve creating DAG-style networks that allow for more than one path to the target. One of these paths typically involve directly feeding forward the input signal. This therefore allows for the gradient to not attenuate and help in solving the vanishing gradient problems [BSF94].